max number of edges:
- n(n-1)/2, for undirected graph
- n(n-1), for directed graph.
Topological Sort
- only make sense if it is a digraph, and also DAG (Directed Acyclic Graph)
- there could be more than one topological sort for a graph
- following is a natural way to get topological sort, besides, we can use DFS to track the finishing order, and it's the reverse order of topological sort.
- ALGORITHM: (O(n + e) + O(n + e) = O(e), e> n generally speaking )
- find the nodes with indegree 0 and put into Q. (O(n + e))
- while Q is not empty
- n = dequeue(Q)
- for each edge starts from n, do (O(e))
- n.adj_node.indegree--
- if (n.adj_node.indgree == 0) enqueue(Q, n.adj_node)
BFS
- application of BFS
- testing Bipartite
- Ford-Fulkerson algorithm for maximum flow problem
- Garbage Collection (refer Cheney's algorithm and here)
- detecting cycle (DFS also works)
- path finding (DFS also works)
- Prim's MST and Dijkstra's Single source shortest path use structure similar to BFS.
- find all neighbor nodes in p2p networks, like BitTorrent
- find people within a given distance 'k' from a person in social networking websites
bfs(G, s) // (O(n + e))
unmark all vertices
v = s // start from here
do
if v is marked, continue
unmark v
put v.adj_node into Q
while Q is not empty
u = dequeue(Q)
if u is not marked, do
mark u and enqueue(Q, u)
while existing unmarked nodes
DFS
- more broadly used than bfs, since it gives more information
- differ with BFS which Q, it uses stack to keep the back tracking info
- two useful thing we can track: the start time and the finishing time, we could do that by just putting its parent node info together into the stack
- applications
- topological sort is the reverse of finishing time
- detecting cycle in a graph is another application of dfs
- for unweighted graph, dfs travel produces Minimum Spanning Tree and All-Pair-Shortest-Path.
- find strong connected graph: every vertex is reachable from every vertex.
dfs(G, s)
mark all vertices as unvisited
push s into stack S
while S is not empty
u = pop(S)
unmark u
for all edges (u, v)
if (v is not visited) push(S, v)
Testing Bipartite (Application of BFS)
Def. An undirected graph G is bipartite if the nodes can be colored blue or white such that every edge has one blue and one white end.
Corollary. A graph is bipartite iff it contains no odd length cycle. That is, no edge between nodes of the same layer, which makes BFS a good application for testing bipartite.
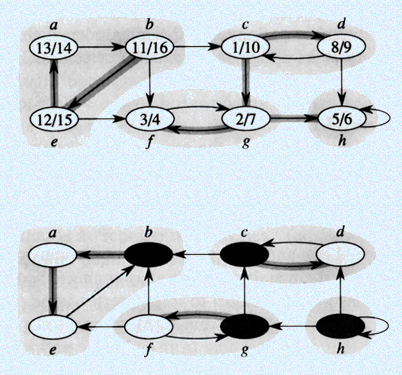
Strongly Connected Components (Application of DFS)
Definition
Given a digraph G=(V, E), a Strongly Connected Components is the subgraph in which any vertex can reach from each other.
Observation
Graph G and its transpose graph have the same Strongly Connected Components. So if vertices u and v are reachable from G iff reachable from its transpose graph.
Algorithm
- DFS(G) computes finishing time for each vertices and produces dfs forest
- GT (transpose G: reverse all edges in G)
- DFS(GT ), but order the vertices in decreasing order of finish time
- the vertices in each DFS tree in the forest of DFS(GT ) is a Strongly Connected Component.
- example (from CLRS book)
- why must do dfs from transpose graph? Consider only nodes {c,d,g} for above graph, if don't dfs to transport graph, and picked up c to do dfs, we get {c,d,g} is a strong connected graph, but it is not.
Reference